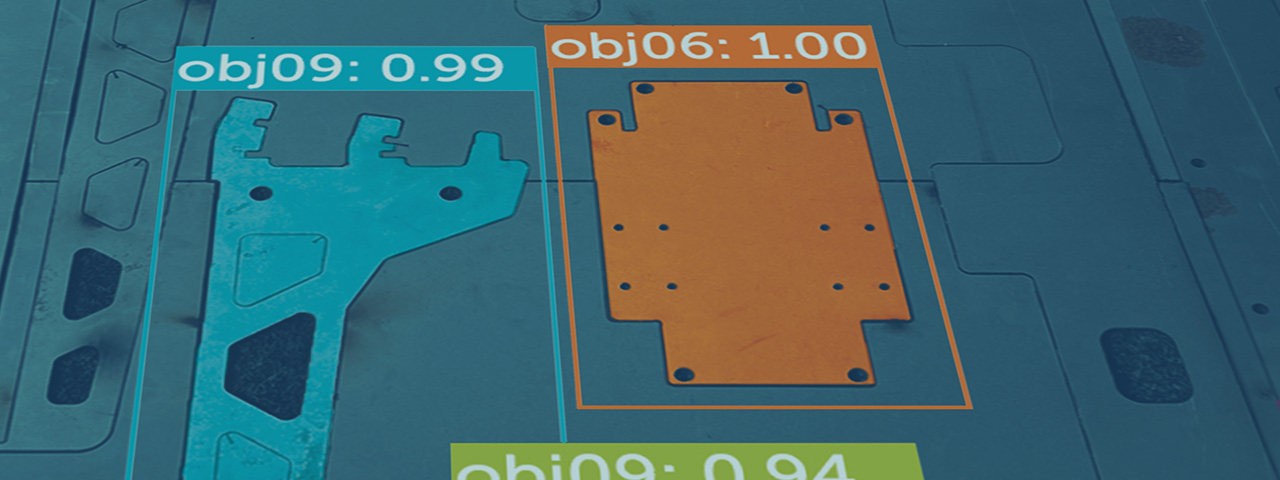
Additionally, the Vision Transformer is able to learn and extract high-level features from images, which makes it well-suited for tasks such as object recognition and classification. There are several variations of the Vision Transformer architecture, includingthe DETR (DEtection TRansformer) and SETR (SEgmentation TRansformer) models. These models are specifically designed for object detection and segmentation tasks, respectively. They are trained using a novel loss function called the set prediction loss, which encourages the model to predict the correct set of objects and their corresponding bounding boxes or segmentation masks.
In summary, the Vision Transformer is a powerful deep learning model that is well-suited for object detection and segmentation tasks. Its ability to processimages in a parallel and efficient manner, as well as its ability to learn andextract high-level features, make it a promising approach for solving complex computer vision problems.


