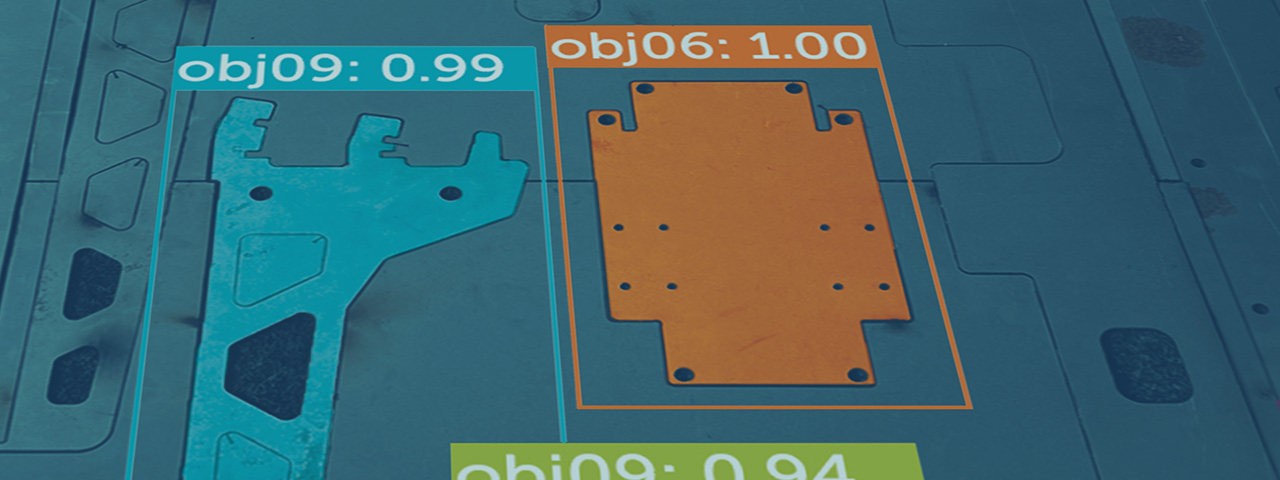
Training current AI models requires a lot of data. Our technology drastically reduces the amount and necessary quality for training current state-of-the-art networks for computer vision tasks, such as classification, detection, segmentation, and object pose estimation. We use a combination of rendering, simulation and modelling approaches to achieve competitive results with very little data. In addition we can drastically reduce the amount of manual labelling – in most cases needing no manual labelling at all.



Benefits
- Faster AI Deployment: With drastically reduced data requirements, users can build and deploy models more quickly.
- Lower Costs: Minimal need for manual labeling and data collection decreases overall operational expenses.
- Greater Scalability: Streamlined data collection and model training allow for easier expansion to new domains.
- Improved Efficiency: Automated rendering and simulation maintain competitive performance while reducing time-consuming data prep.